OpenCitations project

The OpenCitations Project (formally launched by JISC in 2010) and its main product OpenCitations Corpus open repository help to publish bibliographic citation information in RDF and to make citation links as easy to traverse as Web links under a Creative Commons public domain dedication.
__________________________________________________________________________________________________
In the age of Open Access (OA), citation data should be recognized as a part of the Commons, i.e. to be freely and legally available for sharing and placed in an open repository in appropriate machine-readable formats in order to be easily re-used by machines to assist researchers in producing new knowledge. Though, “Despite many changes in scholarly publishing and evidence for an Open Access citation advantage, many faculty are still worried about how their publication choices might affect their case for promotion and tenure” (How can open access work with promotion & tenure?).
Databases of citation data (and bibliographic references within research papers) are among the most attractive and used artifacts in the Scholarly Communication domain. They are one of the main tools used by researchers for gaining knowledge about a particular topic, as well as for analyzing the complex relationships that exist within huge networks of citations of scholarly works.
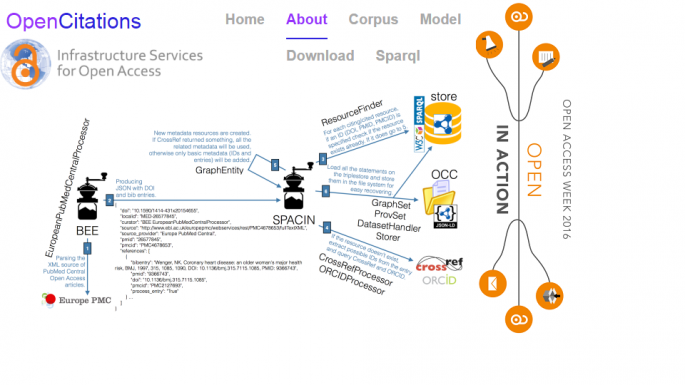
The main premise behind the OpenCitations Project, which has created the OpenCitations Corpus (OCC) - an open repository of scholarly citation data - is to recognize citation data as a part of the Commons.
Under a Creative Commons public domain dedication, OCC (with an integrated OCC SPARQL endpoint and a browsing interface to support data consumers) provides accurate citation information (in RDF) harvested from the scholarly literature.
In 2014, OpenCitations was adopted by the Infrastructure Services for Open Access (IS4OA) as one of its academic OA services.
The current instantiation of the OCC is hosted by the Department of Computer Science and Engineering (DISI) at the University of Bologna.
Since the beginning of July 2016, the OCC has been ingesting and processing the reference lists of scholarly papers available in Europe PubMed Central, and as of October 2016 - the OCC contains 1.521.890 citing/cited bibliographic resources for a total number of 1.884.263 citation links!
A first downloadable dump of the OpenCitation Corpus is now available here (published via Figshare).
All the bibliographic references harvested from the scholarly literature are described using the SPAR (Semantic Publishing and Referencing) Ontologies, according to the OCC metadata document.
SPAR Ontologies* form a suite of orthogonal and complementary OWL 2 DL ontology modules for the creation of comprehensive machine-readable RDF metadata for every aspect of semantic publishing and referencing: document description, bibliographic resource identifiers, types of citations and related contexts, bibliographic references, document parts and status, agents' roles and contributions, bibliometric data and workflow processes.
The newly revised metadata model used for the data stored in the OCC is explicitly aligned with the SPAR Ontologies and other standard vocabularies, such as:
- the FRBR-aligned Bibliographic Ontology (FaBiO) to provide a description of all the metadata of citing/cited bibliographic resources and their related container resources, and metadata about the particular formats in which they have been embodied;
- the Publishing Roles Ontology (PRO) to describe the roles of bibliographic agents/creators related to the bibliographic resources;
- the Bibliographic Reference Ontology (BiRO) and the Citation Counting and Context Characterization Ontology (C4O) to describe the textual content of each reference in the reference list of a citing bibliographic resource;
- the DataCite Ontology is used to define all the identifiers (e.g. DOI, PubMed ID, PubMed Central ID, ORCID, ISSN, etc.) for bibliographic resources and the agents involved;
- the Friend Of A Friend (FOAF) ontology is used to define additional data about agents, such as their given and family names.
All the terms from the aforementioned ontologies are collected within a new ontology called the OpenCitations Ontology (OCO) that groups existing complementary ontological entities from several other ontologies, for the purpose of providing descriptive metadata for the OCC.
All software developed for harvesting citation data is available on GitHub released as open source software (ISC Licence) and can be freely reused in any project and context.
Current project's task are:
- development of tools for linking the resources within the OCC with those included in other datasets (e.g. Scholarly Data and Springer LOD);
- experimenting with the use of multiple parallel instantiations of SPAR Citation Indexer (SPACIN), available in the OpenCitations's GitHub repository, so as to increase the amount of new information that can be processed daily into OCC.
A more detailed introduction of OpenCitations is available at here.
* The SPAR Ontologies website provides also a brief description of the projects, such as: BioTea, DataCite, Data.open.ac.uk, Data on the Web Best Practices WG @ W3C, Europeana Professional, Linked Chemistry, Media type as Linked Open Data, Nature Ontologies, OpenCitation, PDFX, PubChemRDF, Semantic Lancet, Semantic Science, Utopia Documents.
You can point out additional projects that are not listed yet: the project team will be honoured to add them in the website.
__________________________________________________________________________________________________
Contact open OpenCitations Google group (and sparontologies@gmail.com for personal and private communications)
for asking questions about SPARC ontologies, for discussing their possible applications, and even for starting new collaborations.
For being up to date with all the news related with the project, follow Twitter @opencitations
__________________________________________________________________________________________________
Might be also of your interest:
OpenCitations Project (Figshare)
Projects that use SPAR Ontologies for modelling parts of their domain
Freedom for bibliographic references: OpenCitations arise
There are plenty of studies that show an OA citation advantage
The Effect of Open Access on Citation Rates of Self-archived Articles (PDF)
Got an idea for Scientific Research Software? Apply for Catalyst Grant!
